一番簡単な ASCIIコードでは、例えば
a は 97
b は 98
となっています。
ASCIIコードは基本的には0~127までの番号ですが、日本ではカナを扱う必要性から、この2倍の0~255までの番号(1バイト)で表しています。
初期のコンピュータでは、数字・アルファベット・カナだけで十分でしたが、
やがて漢字を扱う事が求められ、256では足らなくなり、256のさらに256倍(つまり2バイト)で番号を割り振り65536文字を表せるようになりました。
(さらに世界各国の文字を表現するため4バイトで表すものもあります。)
日本ではシフトJISとして制定されています。
やがて各国の文字を扱う必要性からそれでも足りなくなり、各種の文字コードが出現してきます。
代表的なものには、EUC/UTF-8/UNICODE(UTF-16)/シフトJIS等があります。
シフトJIS
日本語用の文字コードとしてJIS規格で定められたJISコードを改良したもので2バイトで表現されます。
日本語Windowsではこれがよく使われるので、シフトJISの場合は文字化けを起こすことはありません。
UNICODE
全世界共通で使えるように、世界中の文字を収録する文字コードの規格です。
この中で、どのように符号化するかを取り決めた文字符号化方式として
よく使われるものにUTF-8・UTF-16があります。
UTF-8は、データの中に圧倒的に多い数字やアルファベットを1バイトで表せるよう工夫されていて1~4バイトで表現されます。
単にUNICODEと言った場合はUTF-16を指す場合がほとんどで、1文字は2バイト又は4バイトで表現されます。
EUC
UNIX系で標準的に使われる文字コードの規格の一つです。
日本語の文字を入れたのものをEUC-JPと呼び、日本ではほとんどの場合EUCはこれを指します。
BOM:バイトオーダーマーク (Byte Order Mark)
文字コードの区別がつくように、UNICODEでは、テキストの先頭につける数バイトのデータを付けています。
例えば、UTF-8の場合は 0xEF 0xBB 0xBF の3バイトとなっています。
しかしながら過去との互換性の為、このBOMがないUTF-8も多数出回っています。
文字化け
文字化けを起こす場合は、処理しているプログラムが各種文字コードに対応していない場合に発生します。
日本語Windowsではこれがよく使われるので、シフトJIS以外の場合に発生する事があります。
Excelで拡張子が CSV のファイルを開いた場合に
UTF-8(BOM無し:BOMについては前述)のファイルの場合は文字化けします。
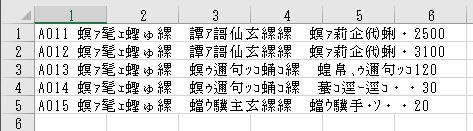
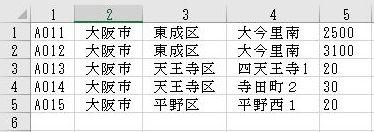
UTF-8(BOM有り:BOMについては前述)のファイルの場合は
Excelが対応しているので文字化けしません。
アテンダントProのCSV処理では、EUC/UTF-8(BOM有り,BOM無し)/UNICODE(UTF-16)/シフトJISに対応しています。
文字コード変換では、文字コードを変換する事ができます。